
苹果AI震撼上线iPhone,进化版Siri却没有ChatGPT,47页技术报告揭秘自研模型所有开发者们被突如其来iOS 18.1测试版砸晕了!没想到,苹果AI这就可以上手尝鲜了,一大波测评刷屏全网。更惊喜的是,苹果AI背后的基础模型47页技术报告,也一并上线了。 一大早,人们期待已久的「苹果AI」首个预览版,正式向开发者们推送了! 
iOS 18.1、iPadOS 18.1、macOS Sequoia 15.1三大系统中,全都植入了苹果AI的最新能力。 那些首批拿到iOS18.1测试版的用户,已经在欢呼雀跃,一波又一波的实测分享铺屏全网。 
最新推出的预览版,包含了许多惊喜(速览版): 全新Siri:唤醒时会在屏幕边缘亮起柔光;与用户交流,可在文本语音之间随意切换;说话者磕磕绊绊时,也能听懂指令;还可以回答有关苹果产品故障排除问题 写作工具(Writing Tools):可在任何场景中,对文本改写、校对和总结摘要。(备忘录、文档、三方APP均可) 专注模式(Reduce Interruptions):仅显示需要即刻看到的通知 照片功能:用自然语言搜索照片,制作影片 为邮件、信息和语音邮件转录生成人工智能摘要 
此外,还有一些功能,苹果表示将在明年推出,包括ChatGPT集成、图像/Emoji生成、照片自动清理、具有屏幕感知的超强Siri。 顺便提一句,目前,iOS18.1测试版(包括iPadOS、macOS)仅限美国开放,国内还未上线。 而且,手机中也只有iPhone 15 Pro、iPhone 15 Pro Max支持新系统。
根据系统介绍,iOS18.1测试版占用的内存空间共15.44GB,其中iOS系统容量12.58GB,而苹果AI仅占用了2.86GB。 这是因为,苹果用在端侧设备上的模型,参数仅有30亿。 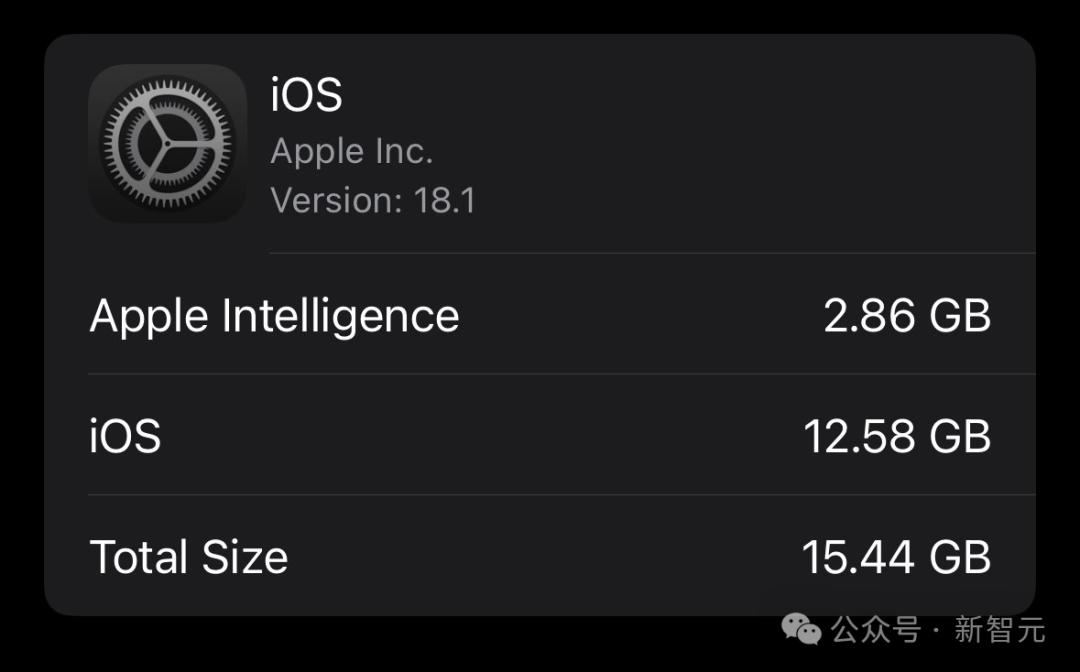
关于模型更详细的介绍,全都藏在了新鲜出炉的苹果AI技术报告中。 48页超长论文中,覆盖了苹果LLM的设计与评估,包括架构、数据管理、预训练和后训练的recipe、优化、功能适应、和评估结果。 
论文地址:https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models.pdf 具体来说,苹果开发了两种全新基础语言模型,构成了苹果AI的核心: 一个是端侧模型AFM-on-device,大约有30亿参数,优化后可以在iPhone和其他终端设备上运行,具备更高效率和响应能力。 另一个是可以在苹果云服务器中运行的更大参数的模型,称为AFM-server,专为密集型任务设计,并使用私人云计算(Private Cloud Compute)的系统来保护用户数据。 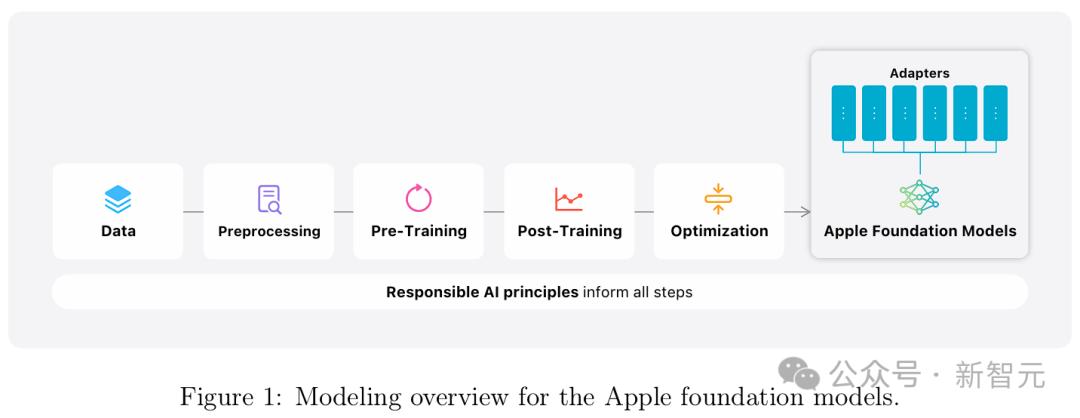
还记得上个月的WWDC大会上,库克向全世界宣布了苹果AI的强大功用,让苹果全家桶得到了史诗级升级。 全网纷纷认为AI瞬间不香了,还是得看苹果AI。 
一般来说,苹果通常会最先发布iOS18主系统。 却没想到,这次苹果竟在这么短的时间内,先将测试版送到首批开发者手中。 这一点,彭博社最新报道中指出,苹果打破一贯的软件发布节奏,是因为苹果AI还需要更多测试时间。 
不知,首批尝鲜者们,都发现了哪些新大陆? 网友实测 苹果科技博主Brandon Butch第一时间,制作了展示iOS18.1测试版中苹果AI功能最全面的视频解说。 
再磕碜的话,都能和顺悦耳 他表示,苹果AI帮助自己找到了一种更好的方式,表达自己想说的话。 
在消息界面中,输入框写下想说的话。 然后全选点击苹果AI按钮,就可以利用写作工具中的「友好的」,AI立刻将这段话的语气变得更加婉转。 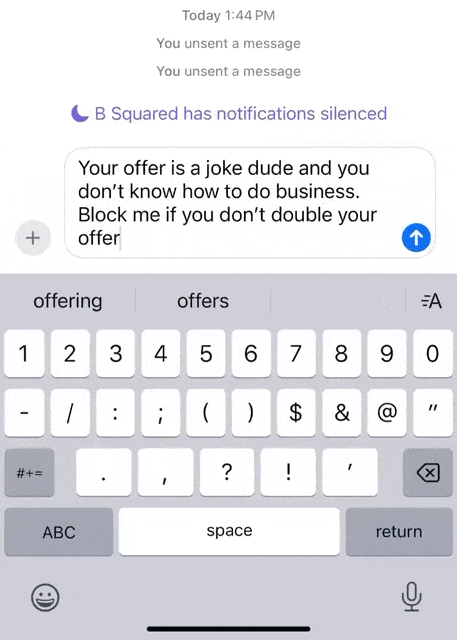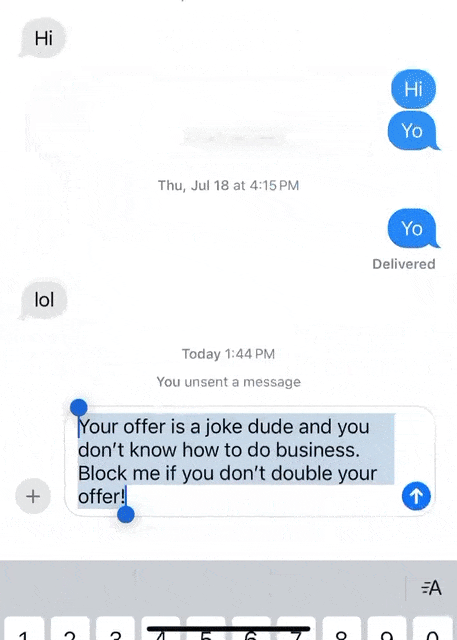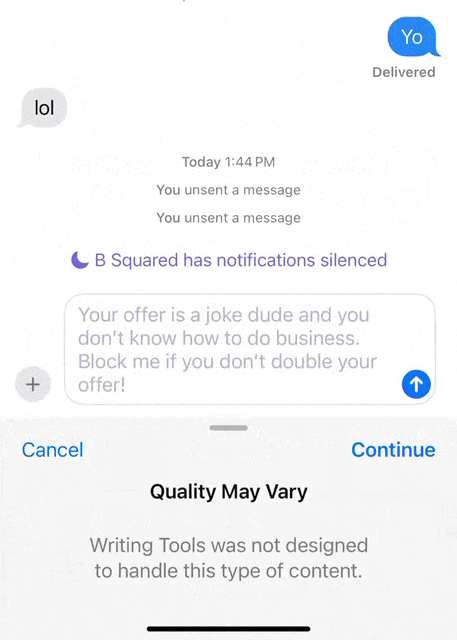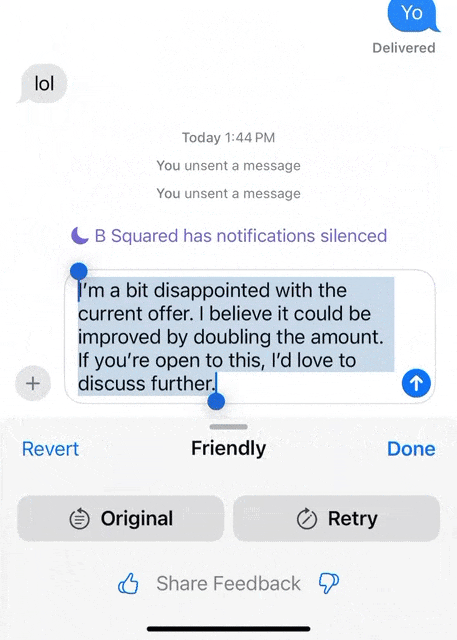
再来看另一位网友,特意写了一句脏话,让AI改写后舒坦了许多。 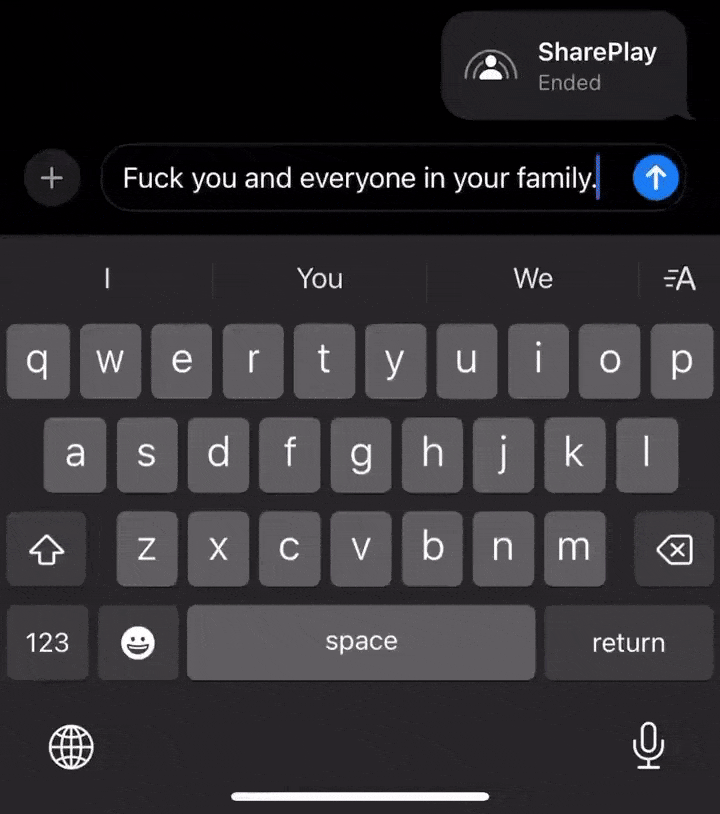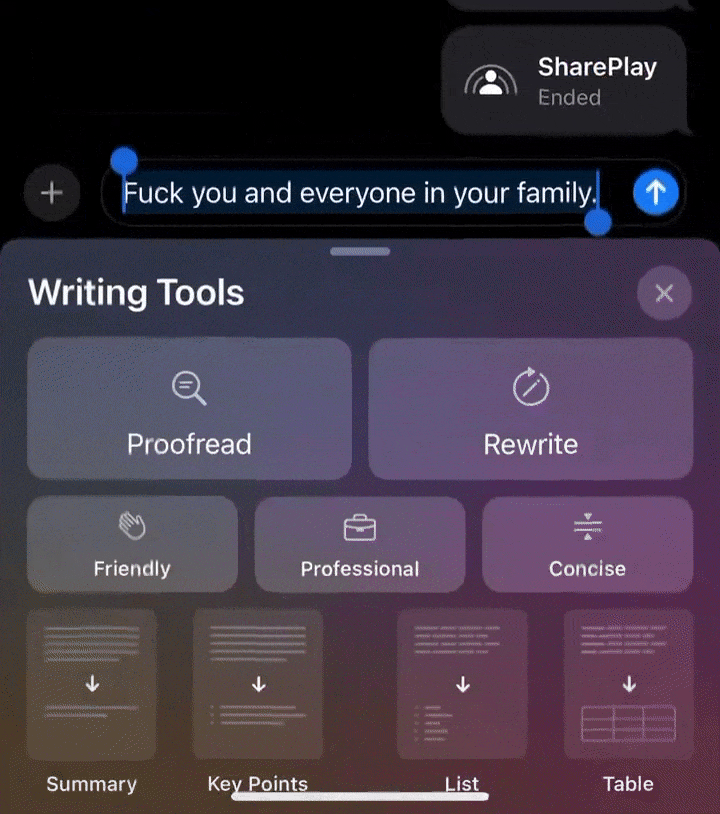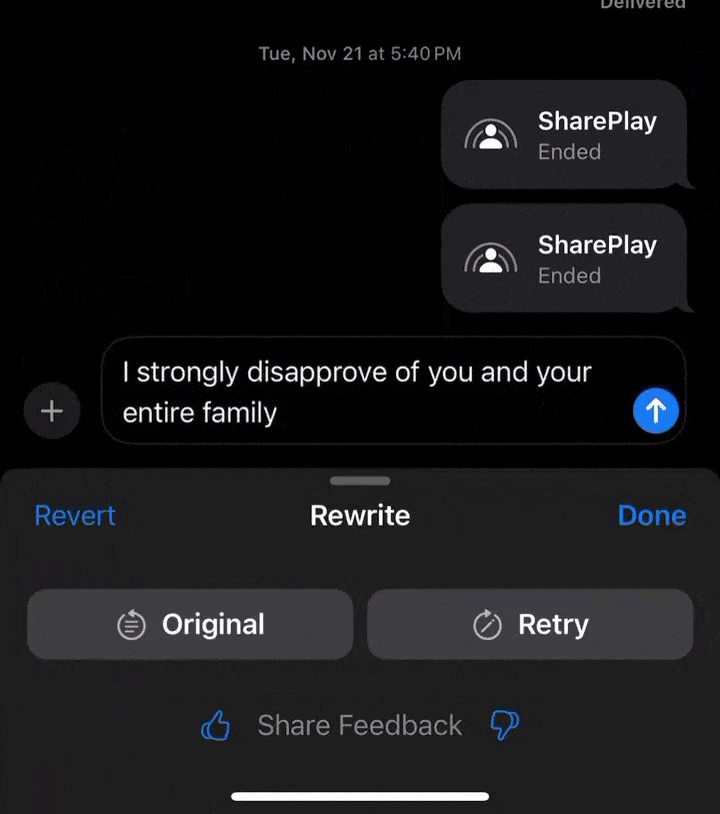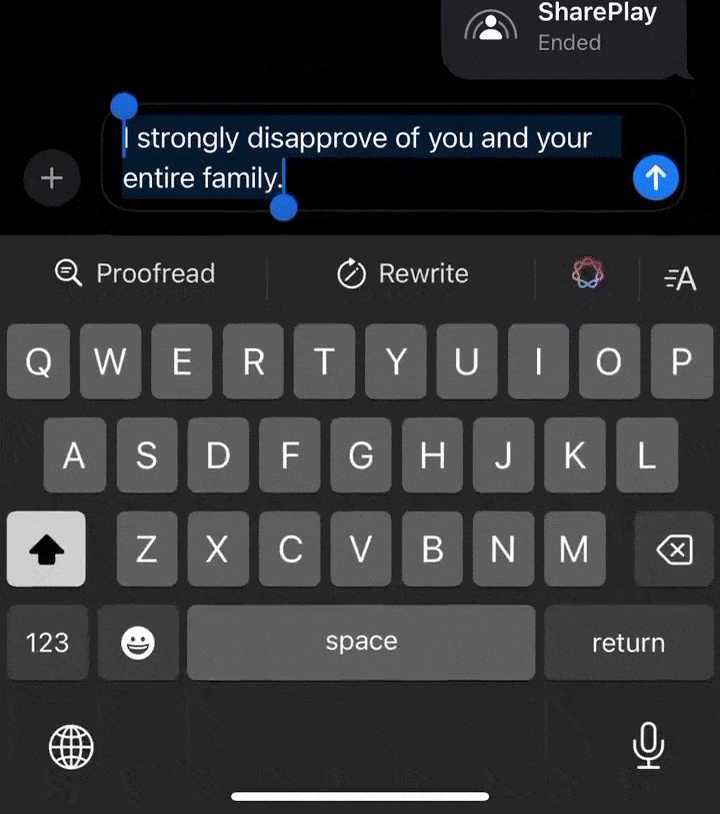
语法错字校对 另外,Butch惊叹道,Grammarly已经被扼杀了,这才是真正的苹果AI。 
就看下面这段话中,informutive拼写错误,what首字母没有大写,还有what do you think末尾应该是问号,而不是句号。 可以看出,苹果AI全都帮你纠正过来了。 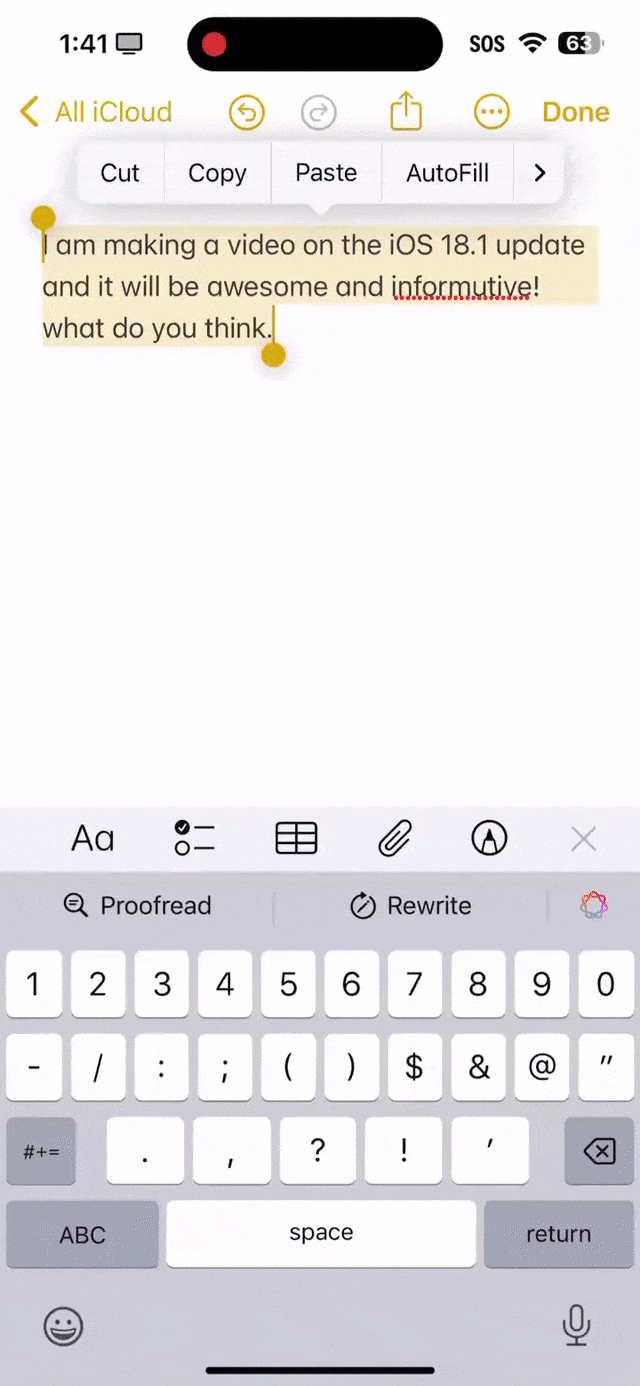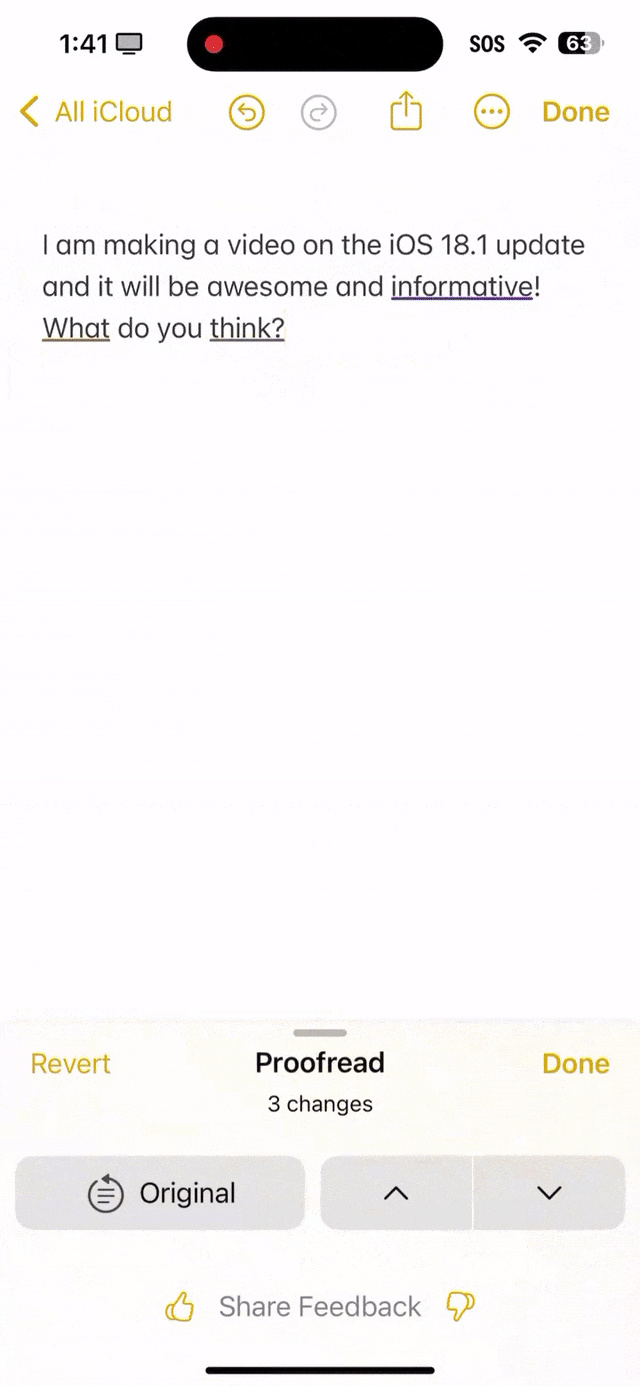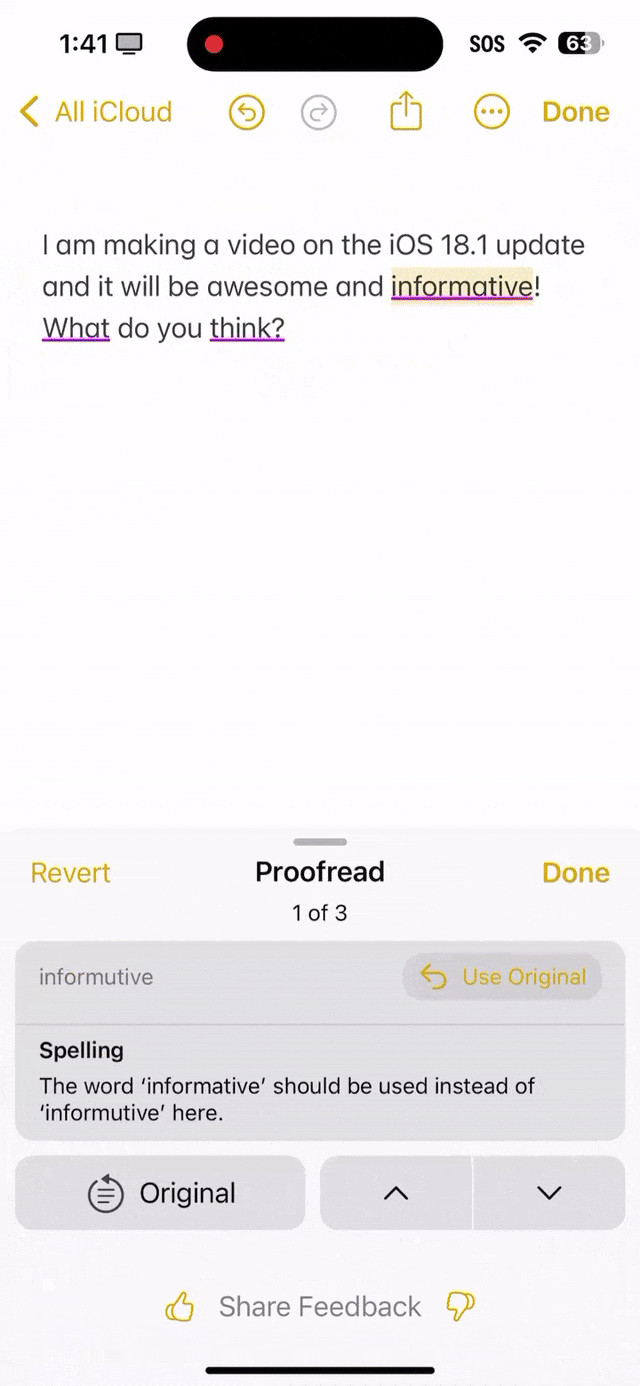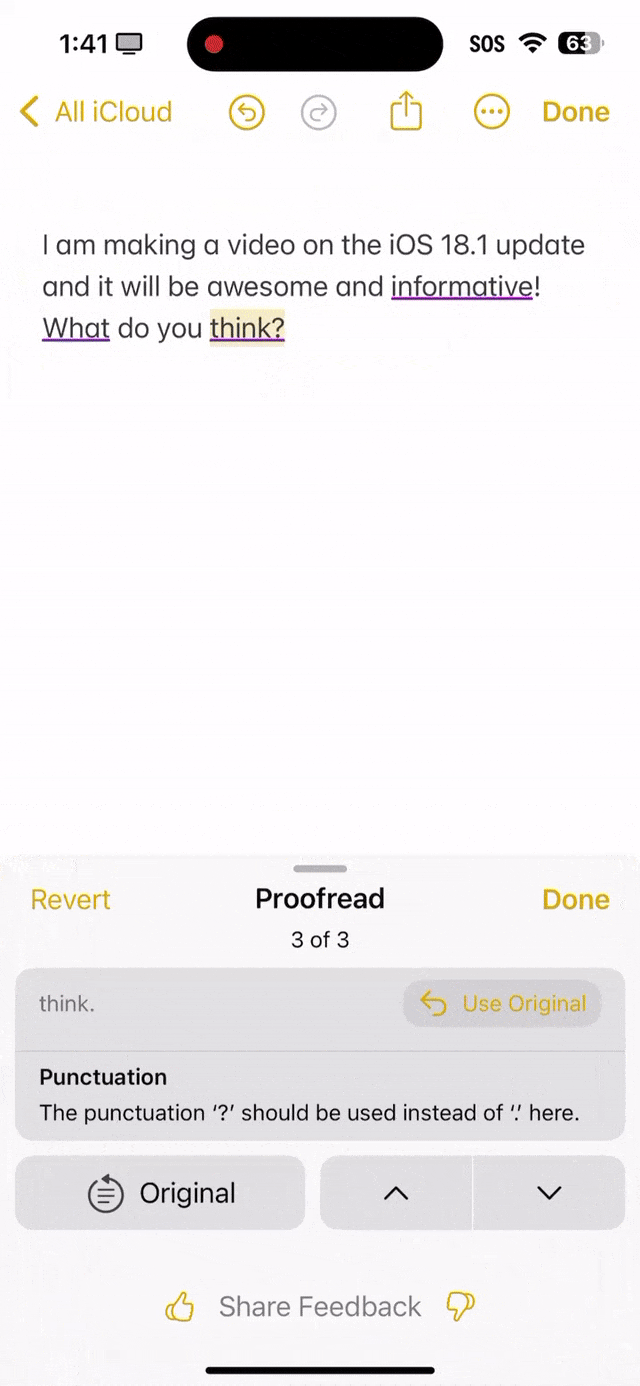
还有邮件中苹果AI能力,听着就让人疯狂。 
同样支持如上备忘录、信息中的写作工具的能力,包括校对、重写等等。 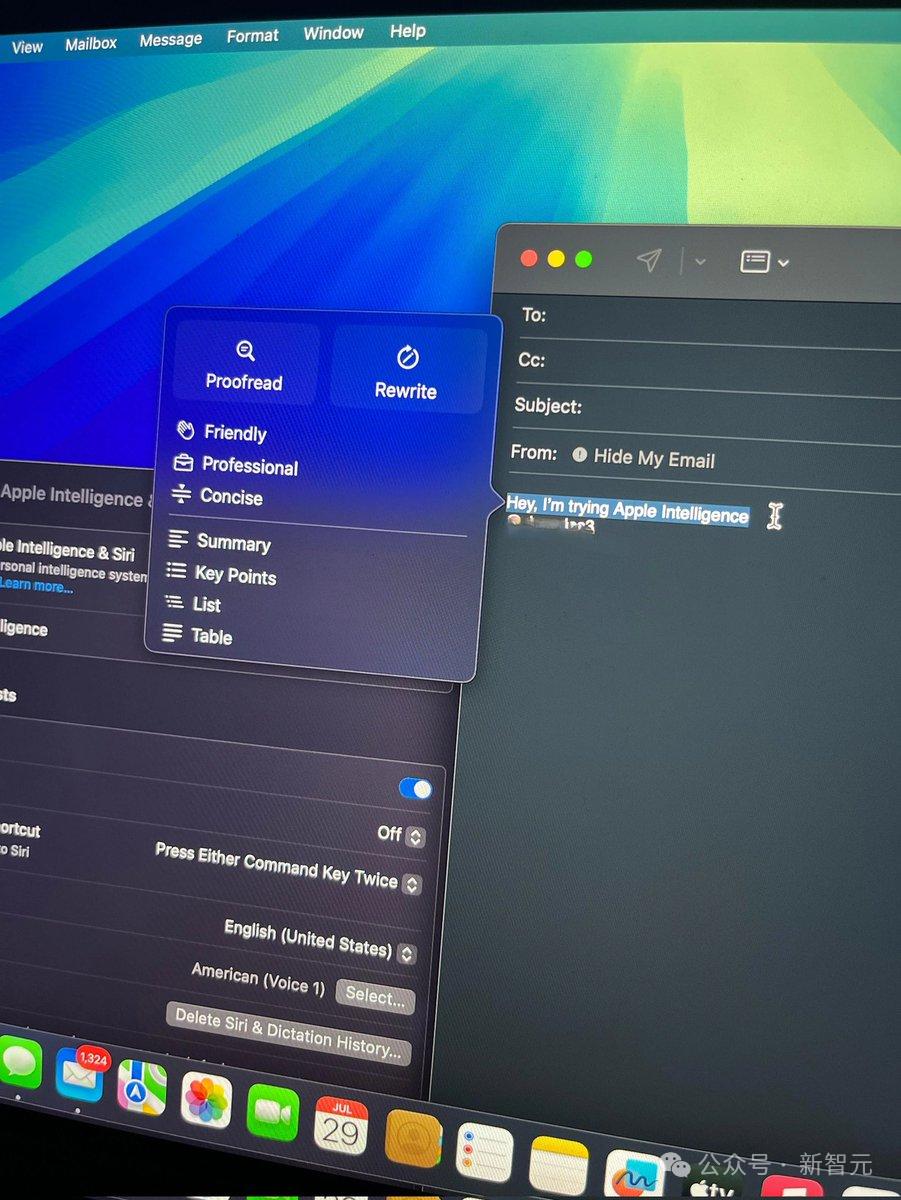
一封邮件的总结,会在最上面呈现出来。 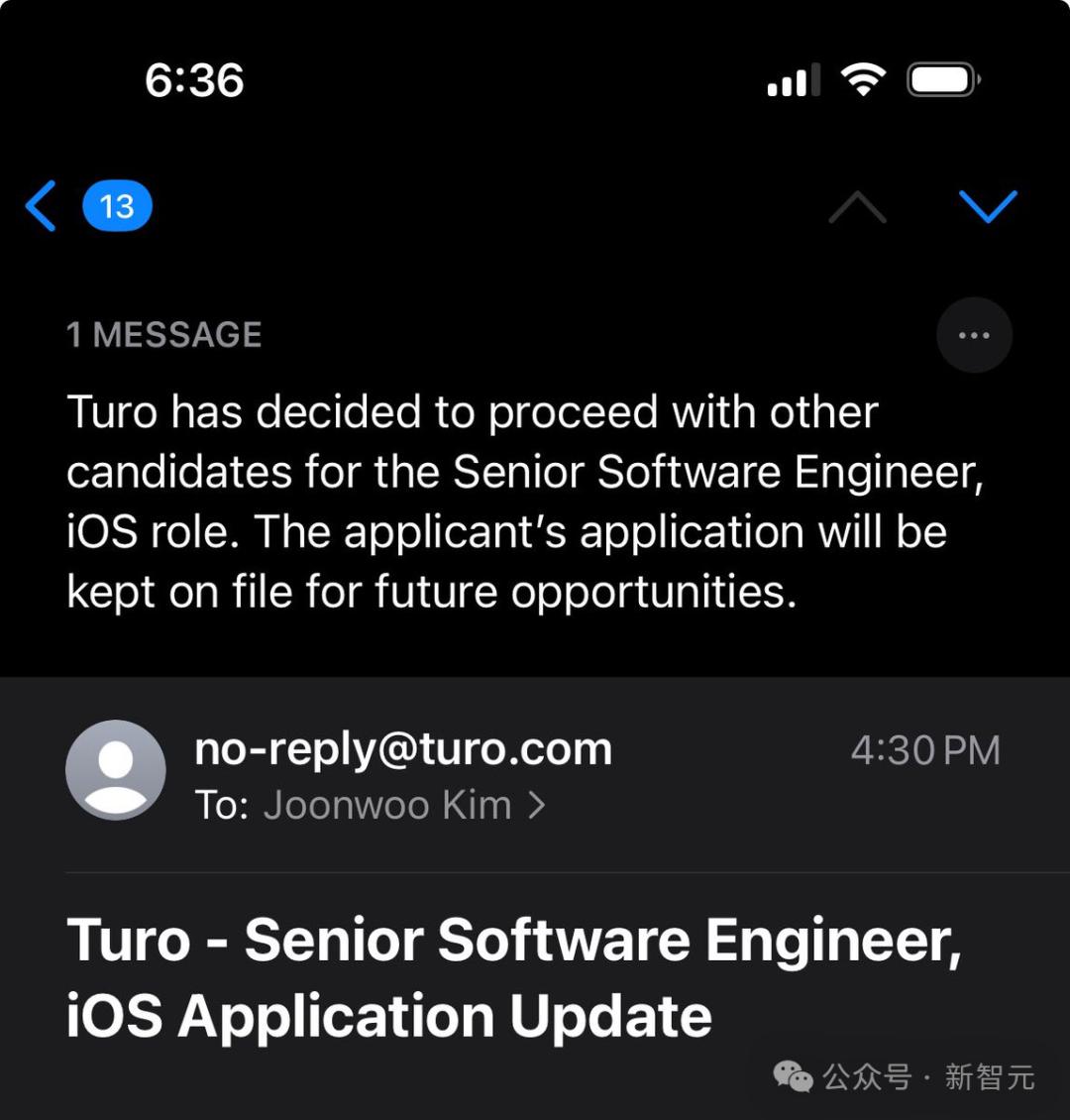
苹果AI写作工具的动画效果「非常苹果」,比起模型回应时的密集标token流,一切显得那么平滑。 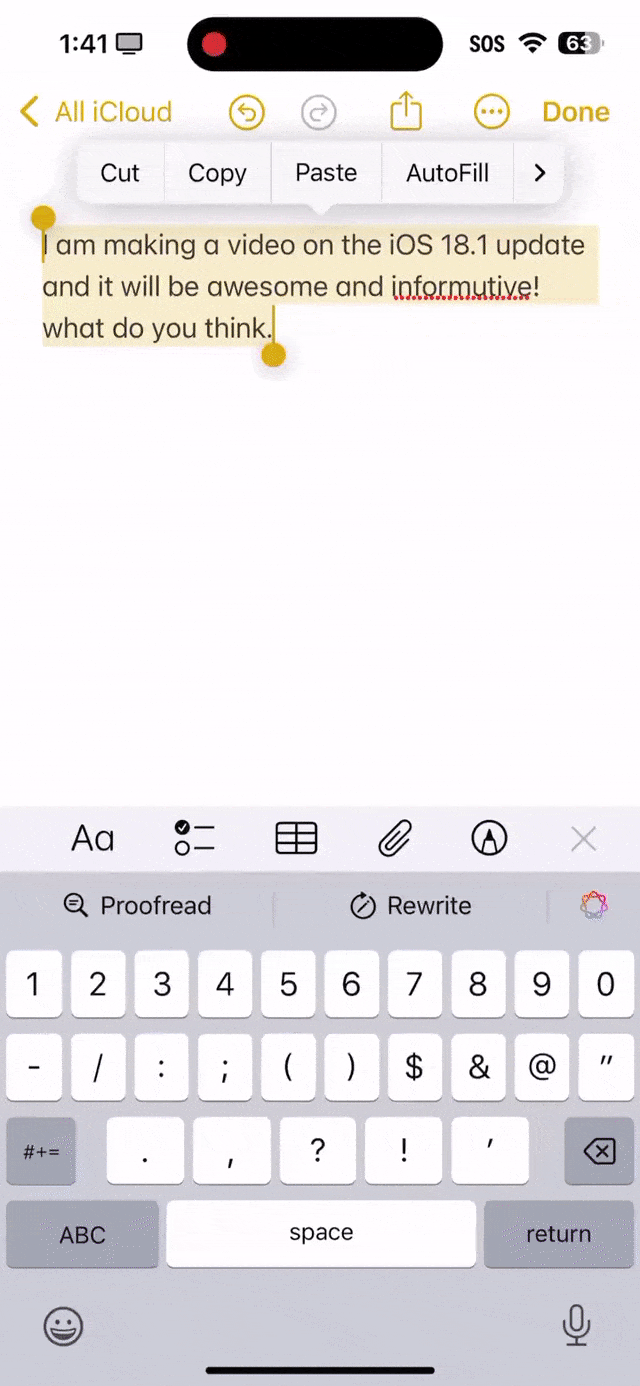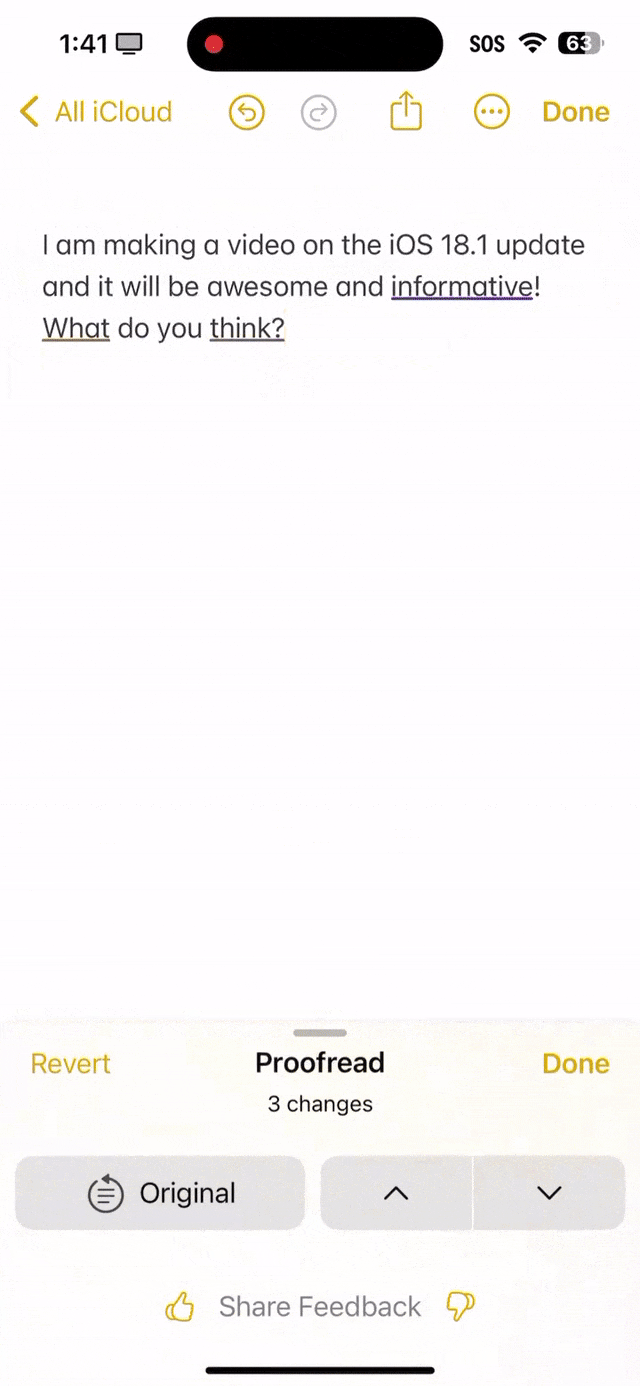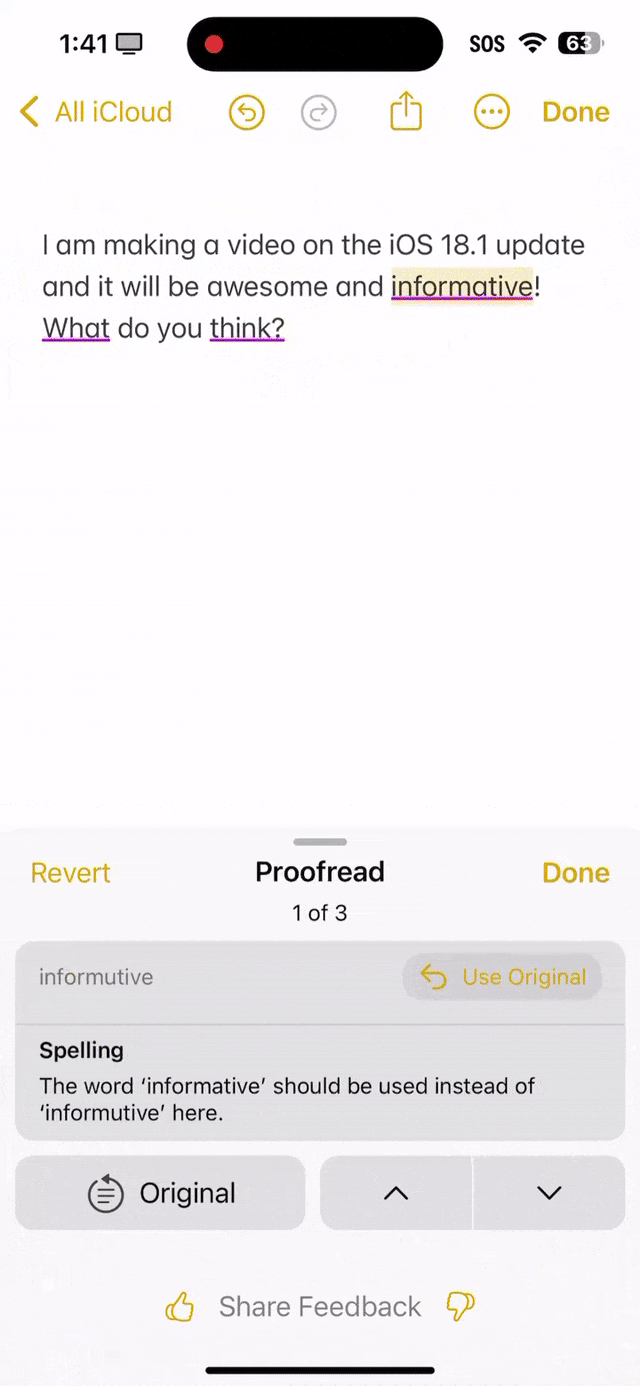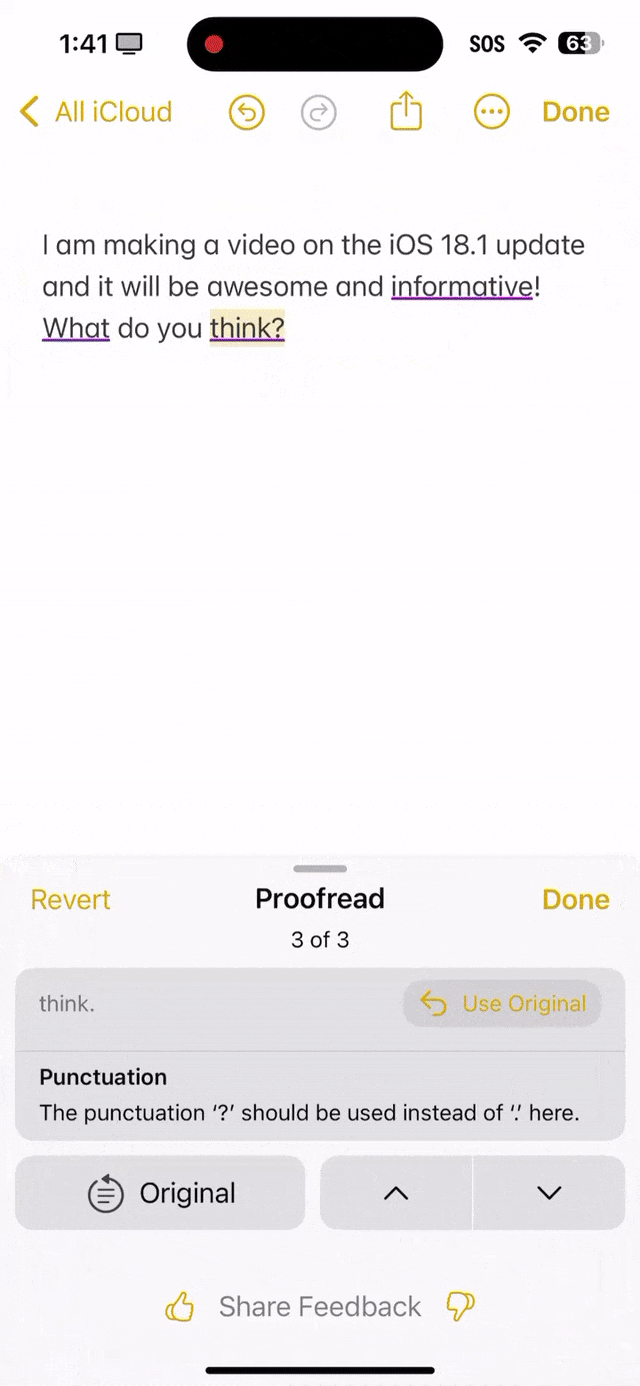
全新Siri,反应超丝滑 再看呼叫Siri的屏幕边缘效果,不得不说苹果你是最懂设计的。 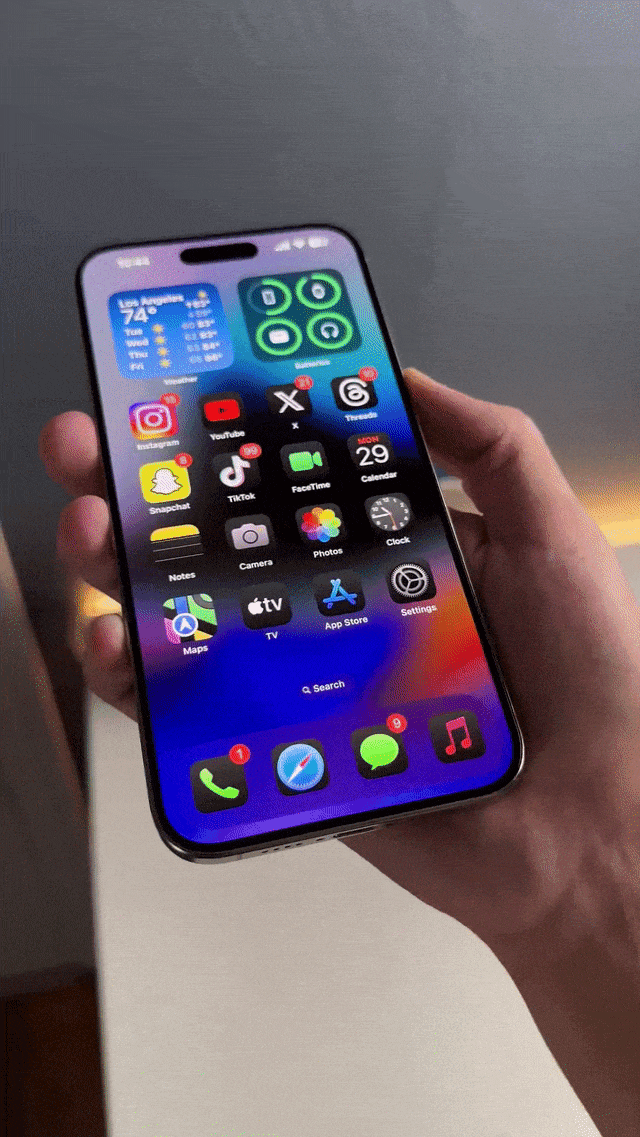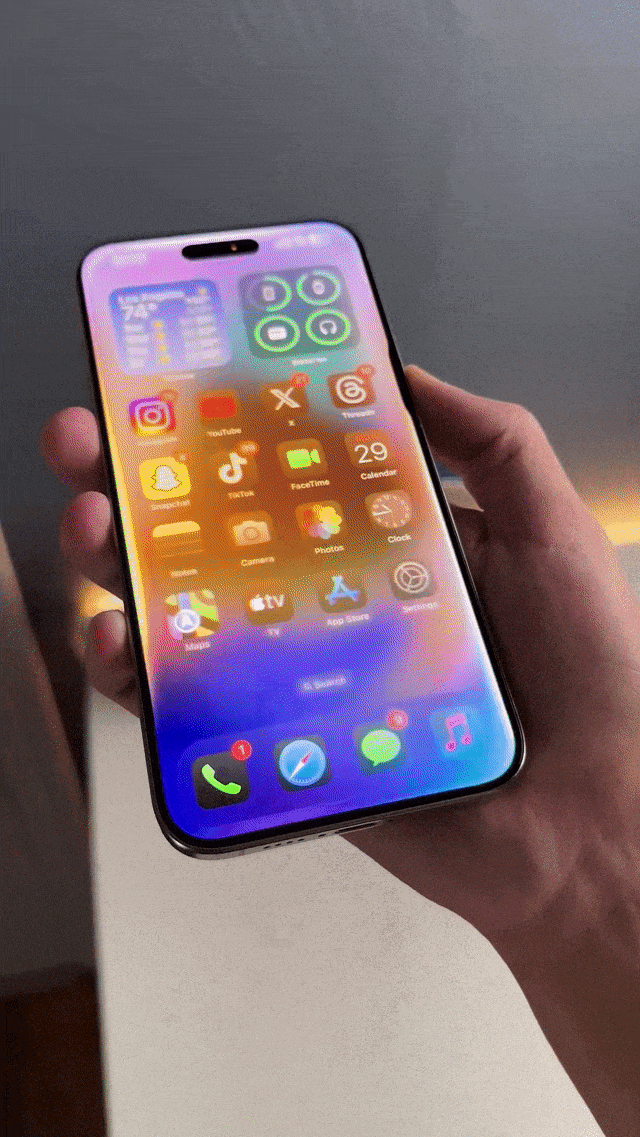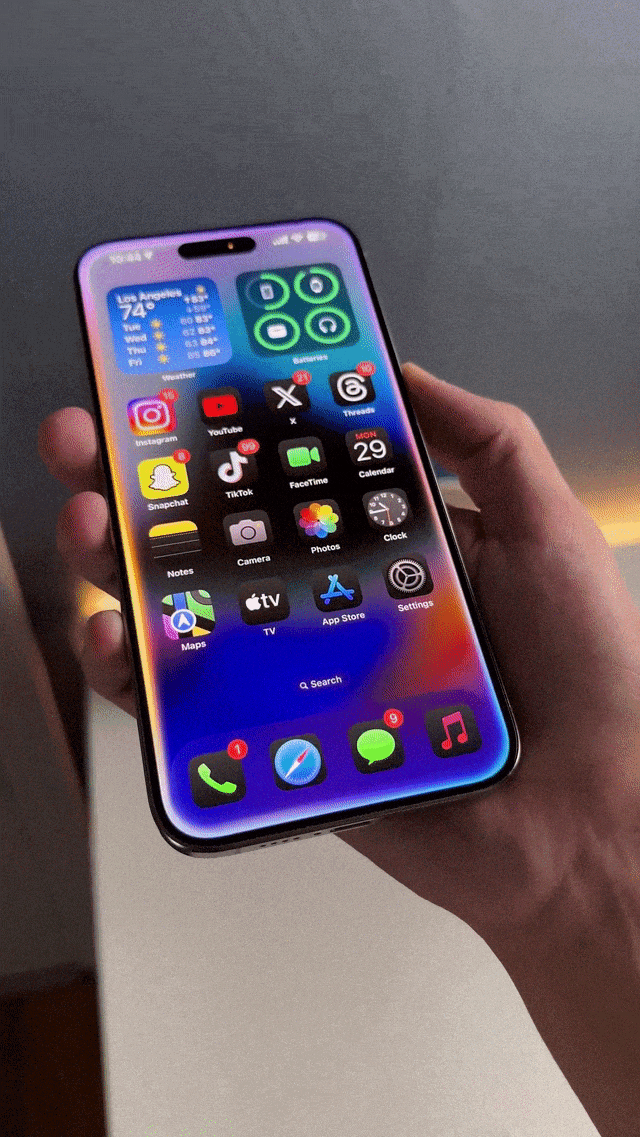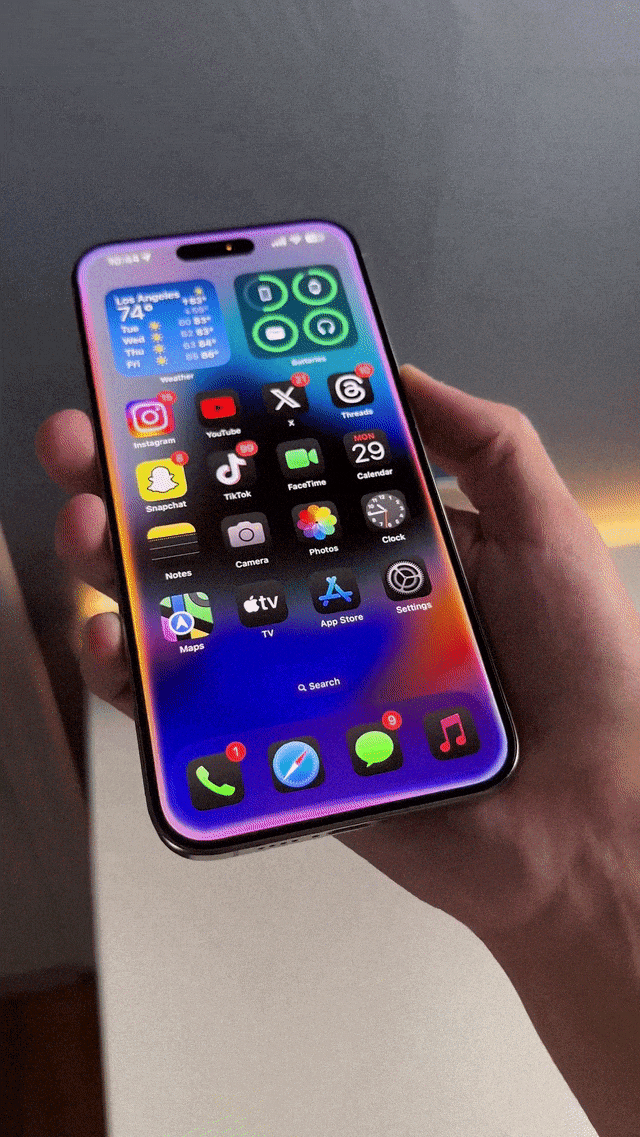
再来看iPad版的Siri。 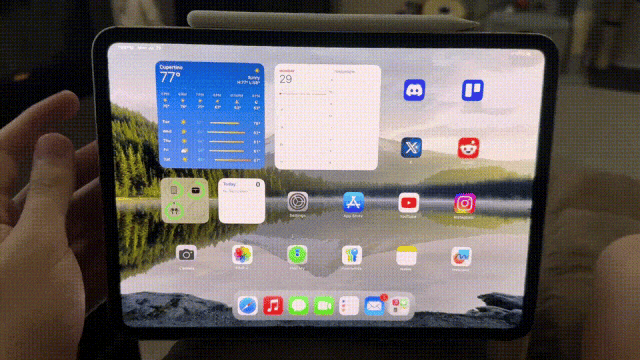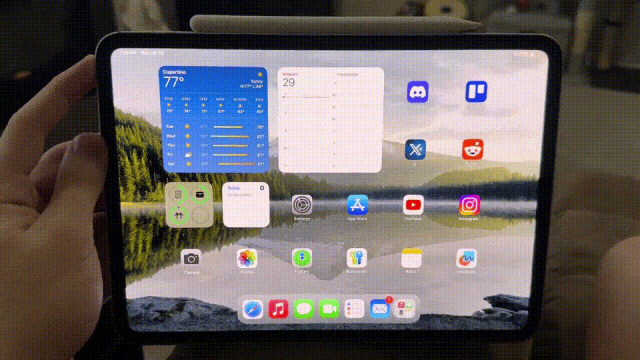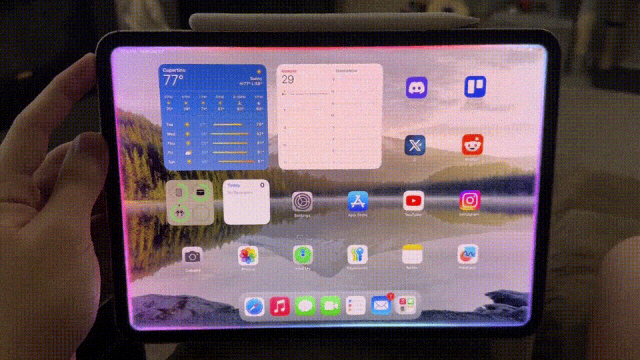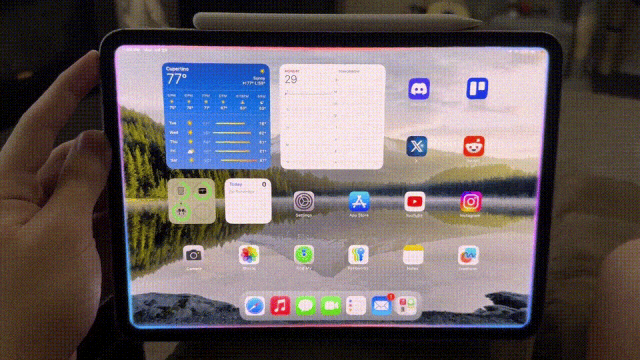
Humane的AI工程师,苹果前工程师测试Siri后称赞道,苹果AI速度非常、非常地快。 
唤醒Siri,问一问埃菲尔铁塔有多高?它位于哪里? 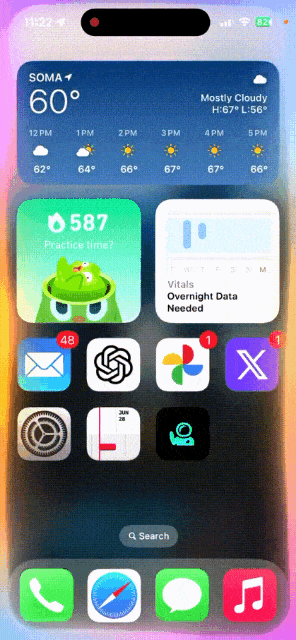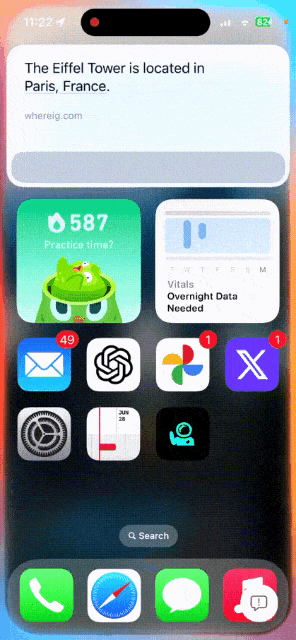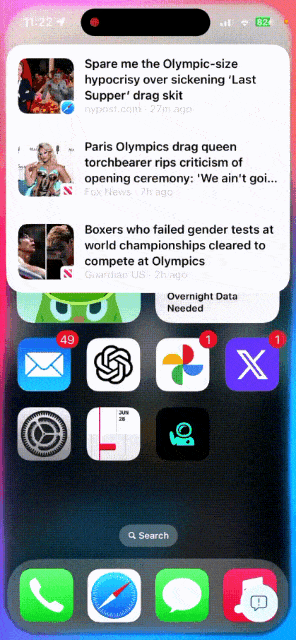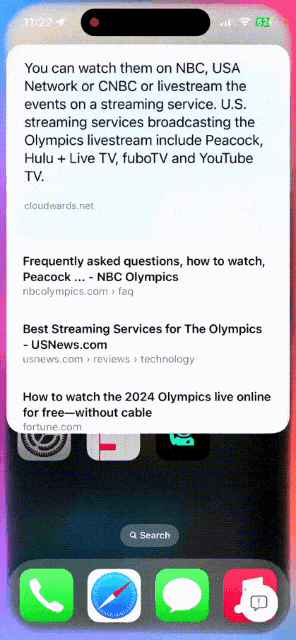
顺便再让它推送一些关于巴黎奥运会近期新闻,以及如何观看奥运会赛事。 不一会儿功夫,苹果AI都给解答了。 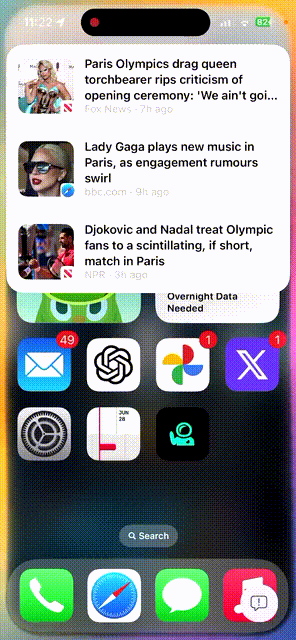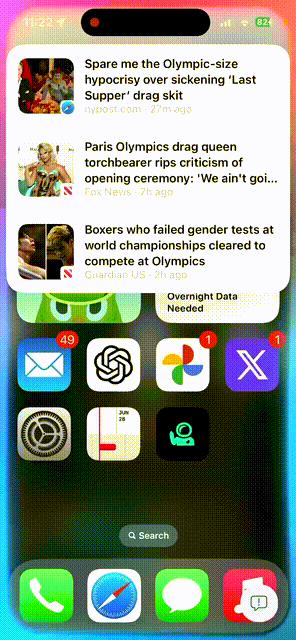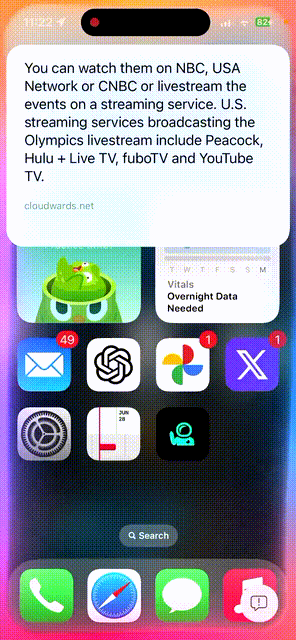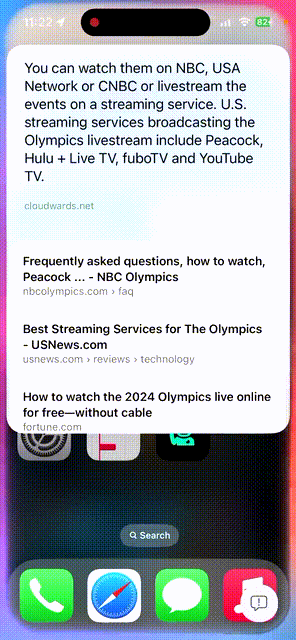
AI转录总结,重要电话内容不怕遗漏 此外,苹果AI还可以帮你将电话转录成笔记,记录下你所谈论的内容。 
如果按下录音按钮,主叫方和受话方都会播放提示音,提示通话将被录音。 
录音完成后,可直接行通知浮窗进入查看录音内容。 
专注模式 使用苹果AI来自动分析通知内容,检测重要通知! 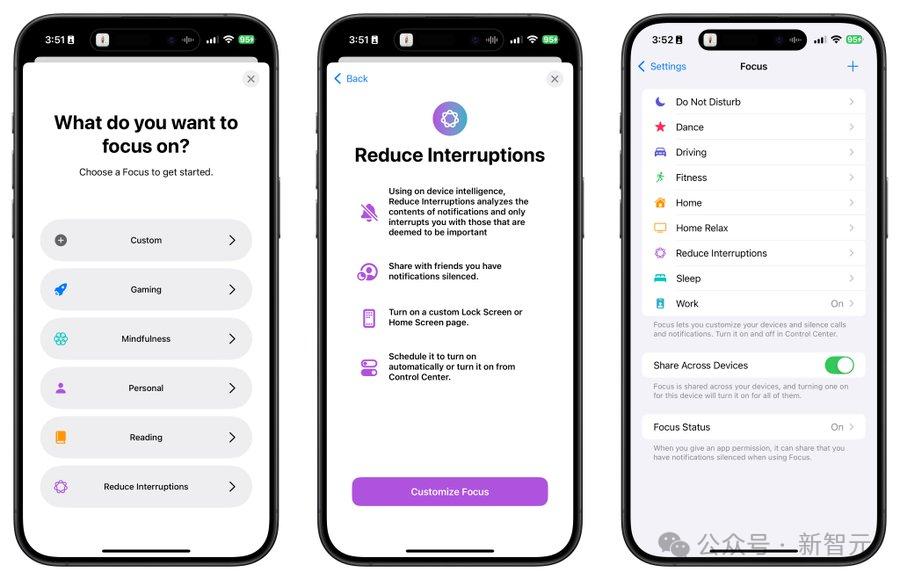
重要人的通知,就会pin在屏幕最下方。 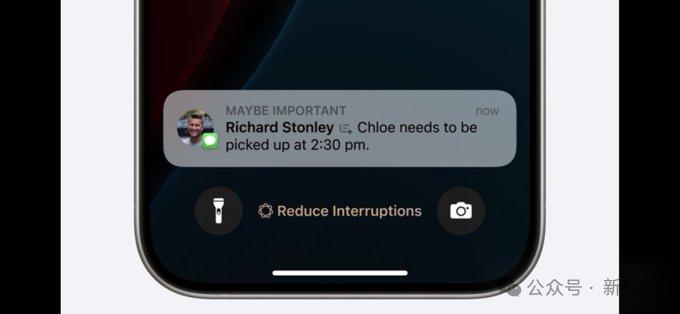
照片搜索,吐槽不少 当然了,iOS18.1之所以最先推出,就是为了让开发者们多多测试,去发现报告问题,更好地改进苹果AI能力。 这不,一位YouTube博主在测试照片功能时,却发现Siri依旧「智障」。 
博主最先问了一句,「Siri向我展示2022年感恩节旅行的照片」。Siri却回答:打开健康应用程序的次数.... 然后,他再次重复了刚刚的问题,「Siri,从照片中查找关于感恩节的照片」。 
搞笑的的是,Siri直接从互联网上搜索了一大堆感恩节相关的图片。 当他再次问道,「Siri,向我展示去台湾旅行的照片」,Siri将原话听成了关键词,从网上搜索了「My Trip to Twaiwan」。 然后他继续问,Siri依旧不知所云。 固执的博主,破碎的Siri,简直笑不活了..... 正如开头所述,能够把苹果AI装进终端设备,背后是来自团队自研的基础模型,在发光发热。 iPhone的AI革命:30亿参数装进口袋 具体来说,AFM是一款基于Transformer架构的仅解码器稠密模型。 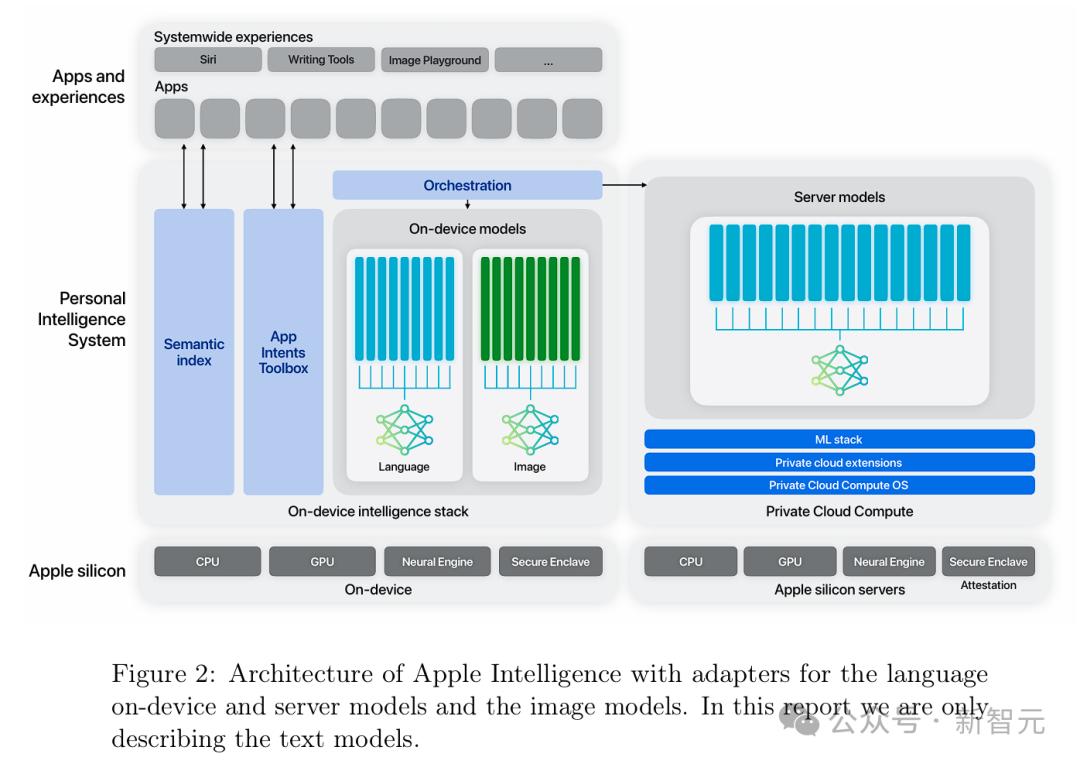
其设计思路如下: 共享输入/输出嵌入矩阵,减少参数的内存使用 使用RMSNorm的预归一化,提高训练稳定性 查询/键归一化,提高训练稳定性 具有8个键值头的分组查询注意力(GQA),减少KV缓存的内存占用 更高效的SwiGLU激活 基础频率为500k的RoPE位置嵌入,支持长上下文 
适配器架构 通过使用LoRA适配器,苹果的基础模型可以动态地根据当前任务即时专门化。 这些小型神经网络模块可以插入基础模型的各个层,用于对模型进行特定任务的微调。 为了促进适配器的训练,苹果还创建了一个高效的基础设施,使得基础模型或训练数据更新或需要新功能时,能够快速添加、重新训练、测试和部署适配器。 优化 由于需要满足用户的日常使用,因此团队采用了多种优化和量化技术,在保持模型质量的同时,显著减少了内存占用、延迟和功耗。 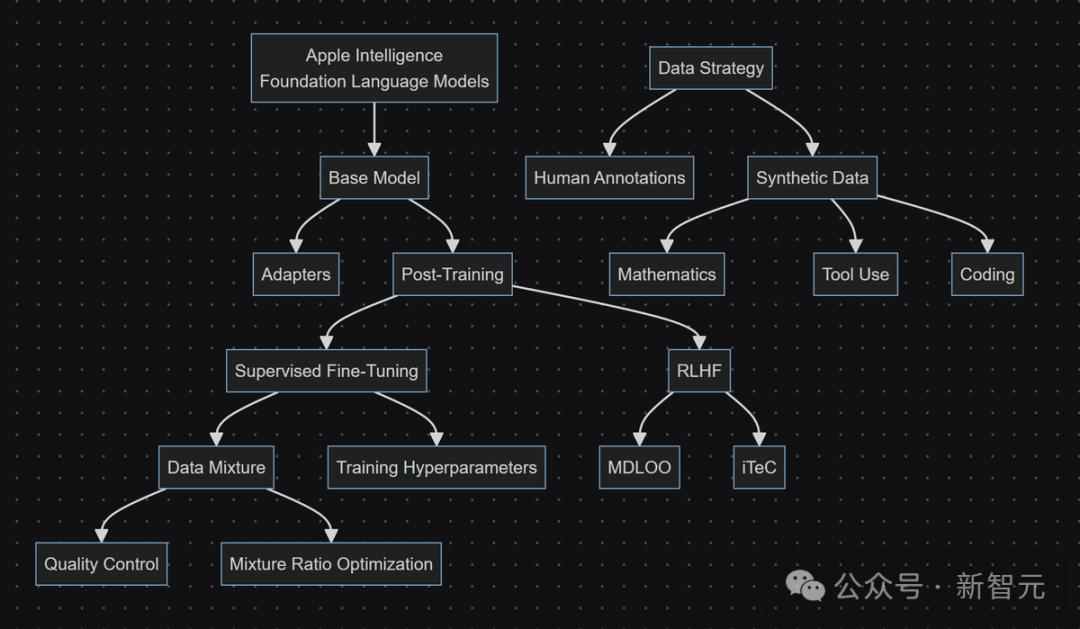
方法 在后训练阶段,苹果对模型进行了压缩和量化,平均每个权重低于4位。 量化后的模型通常会有一定程度的质量损失。因此,研发团队并不是直接将量化模型交给应用团队进行功能开发,而是附加了一组参数高效的LoRA适配器来恢复模型质量。 然后,各产品团队会通过从精度恢复适配器(accuracy-recovery adapters)初始化适配器权重,微调其特定功能的LoRA适配器,同时保持量化的基础模型不变。 值得注意的是,训练精度恢复适配器是样本高效的,可以看作是训练基础模型的迷你版本。 其中,在适配器的预训练阶段,只需要大约100亿个token(约占基础模型训练的0.15%)即可完全恢复量化模型的能力。 由于应用适配器将从这些精度恢复适配器进行微调,它们不会产生任何额外的内存使用或推理成本。 关于适配器的大小,团队发现秩为16的适配器在模型容量和推理性能之间提供了最佳平衡。 然而,为了提供更多的灵活性,苹果提供了一套不同秩的精度恢复适配器供应用团队选择。 量化 精度恢复适配器带来的另一个好处是它们允许更灵活的量化方案选择。 过去在量化大语言模型时,通常会将权重分成小块,通过对应的最大绝对值来规范每个块,以过滤掉异常值,然后在块的基础上应用量化算法。 虽然较大的块大小会降低每个权重的有效位数并提高吞吐量,但量化损失也会增加。为了平衡这种权衡,通常将块大小设置为较小的值,如64或32。 但在苹果的实验中,团队发现精度恢复适配器可以显著改善这种权衡的帕累托前沿(Pareto front)。 对于更激进的量化方案,更多的错误将被恢复。因此,苹果能够为AFM使用高效的量化方案,而不必担心模型容量的损失。 混合精度量化 每个Transformer块和AFM的每一层中都有残差连接。因此,不太可能所有层都具有相同的重要性。 基于这一直觉,苹果通过将某些层推向2位量化(默认是4位)来进一步减少内存使用。 平均而言,AFM设备上的模型可以压缩到每个权重大约3.5位(bpw)而不会显著丧失质量。 在生产中,苹果选择使用3.7bpw,因为这已经满足了内存需求。 评估结果 预训练 表2展示了AFM-on-device和AFM-server在HELM MMLU v1.5.0上的结果,该测试在57个科目中进行5样本多项选择题回答。 
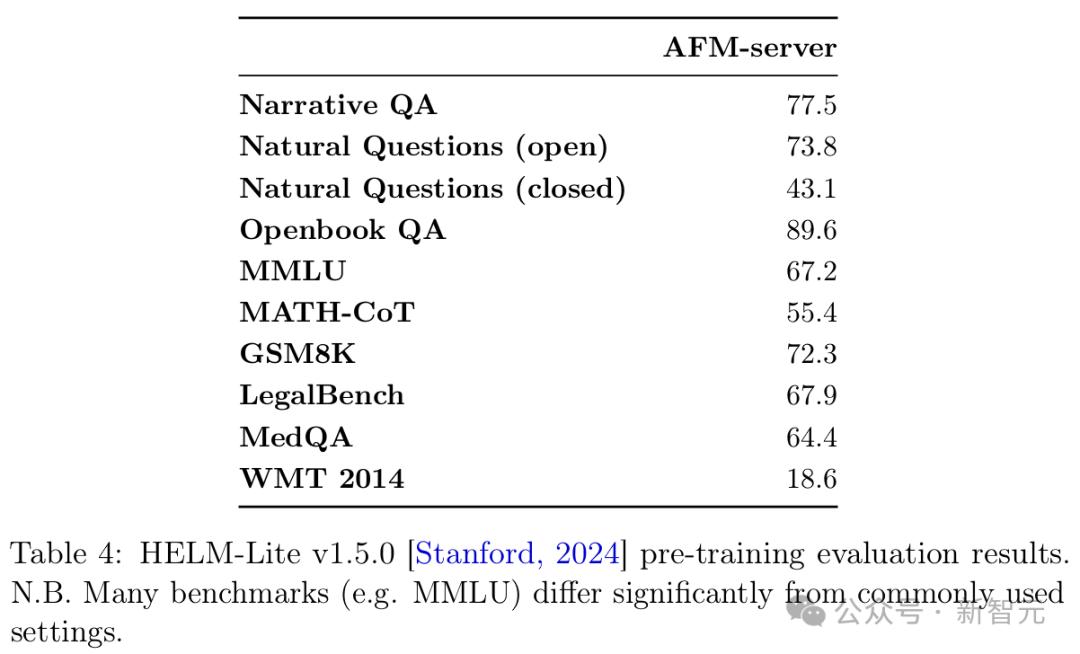
表3和表4分别展示了AFM-server在HuggingFace OpenLLM排行榜V1,以及HELM-Lite v1.5.0基准上的结果。
可以看到,AFM预训练模型有着强大的语言和推理能力,从而为后训练和特征微调提供了坚实的基础。 后训练 人类评估 对于苹果AI的应用场景来说,人类评估更贴近用户体验。 为了评估模型的一般能力,团队收集了1393个全面的提示集。 这些提示可谓包罗万象,涵盖了不同类别以及不同难度级别,包括:分析推理、头脑风暴、聊天机器人、分类、封闭式问题回答、编码、提取、数学推理、开放式问题回答、重写、安全性、总结和写作。 图3展示了AFM与开源模型(Phi-3、Gemma-1.1、Llama-3、Mistral、DBRX-Instruct)和商业模型(GPT-3.5和GPT-4)的比较。 
结果发现,人类评估者更偏爱AFM模型而不是竞争对手模型。 特别是,尽管AFM-on-device的模型尺寸小25%,但与Phi-3-mini相比,其胜率为47.7%,甚至超过了参数数量超两倍的开源强基线Gemma-7B和Mistral-7B。 与闭源模型相比,AFM-server也表现出了一定竞争力,对GPT-3.5的胜率超过50%,平局率为27.4%。 指令跟随 指令跟随(Instruction following, IF)是苹果团队对语言模型寄予厚望的核心能力,因为现实世界的提示或指令通常都很复杂。 这里,团队采用的公共IFEval基准,可以评估大语言模型在生成响应时能否精确遵循提示中的指令。其中通常包括对响应的长度、格式和内容等方面的具体要求。 如图4所示,AFM-on-device和AFM-server在指令级和提示级准确性上都表现出色。 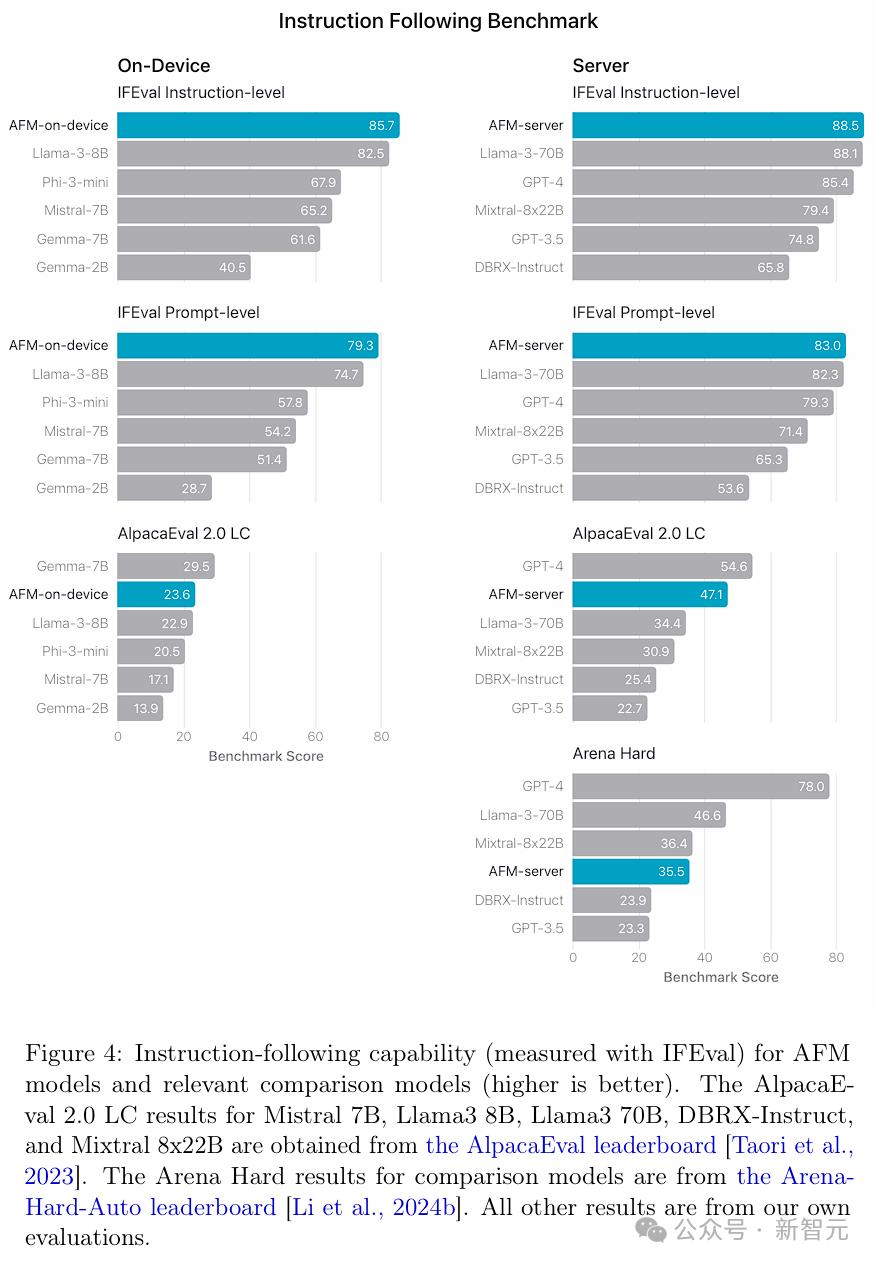
此外,苹果团队还在AlpacaEval 2.0 LC基准测试上对AFM模型进行了基准测试,以衡量其一般指令跟随能力,结果表明其模型具有很强的竞争力。 工具使用 在工具使用的应用场景中,模型在收到用户请求和一系列带有描述的潜在工具列表后,可以通过提供结构化输出来选择调用特定工具,并指定工具名称和参数值。 团队通过函数调用的本地支持,使用AST指标在公共Berkeley Function Calling Leaderboard基准测试上对模型进行了评估。 如图5所示,AFM-server在整体准确性上表现最佳,超越了Gemini-1.5-Pro-Preview-0514和GPT-4。 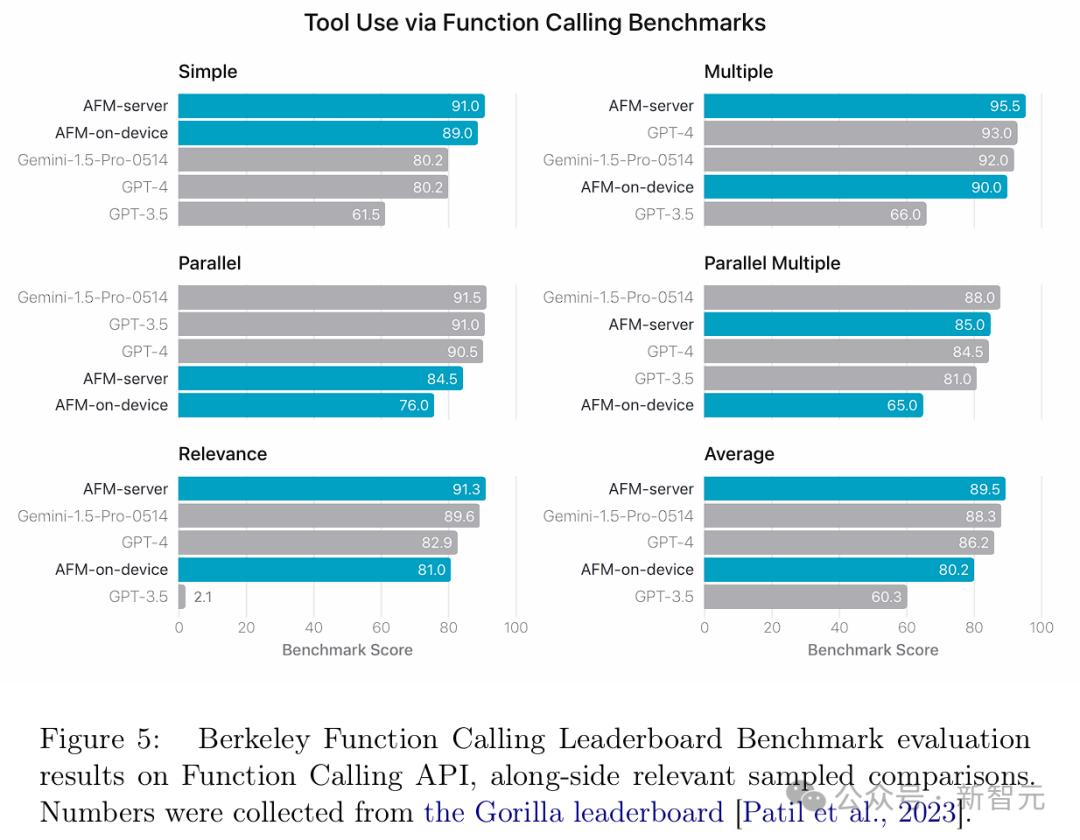
写作 写作是大语言模型最重要的能力之一,因为它能够支持多种下游应用,如改变语气、重写和总结。 团队在内部的总结和写作基准测试中评估了AFM的写作能力。并遵循LLM-as-a-judge的方法,为每个总结和写作任务设计了评分指令,并提示GPT-4 Turbo为模型响应打分,评分范围为1到10。 如图6所示,AFM-on-device在与Gemma-7B和Mistral-7B的比较中表现出相当或更优的性能。而AFM-server则显著优于DBRX-Instruct和GPT-3.5,甚至与GPT-4不相上下。 值得注意的是,使用LLM评分会存在一些限制和偏见,例如长度偏见。 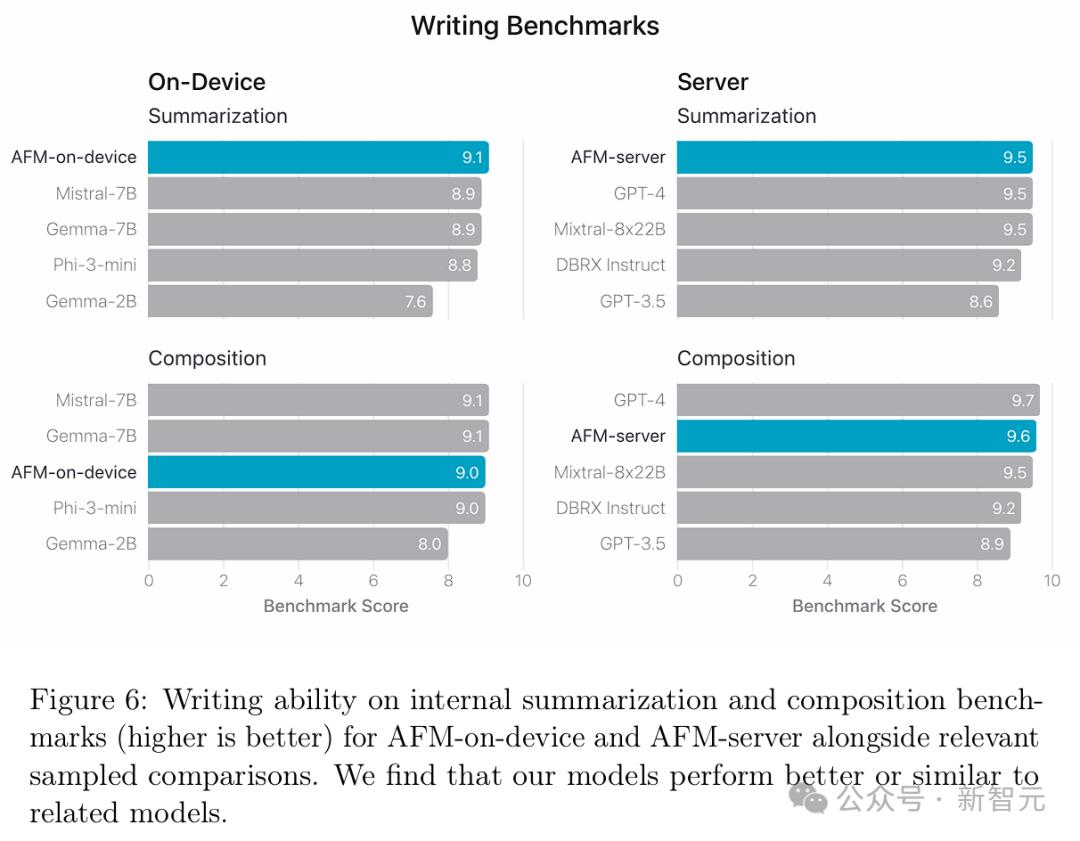
数学 在图7中,团队比较了AFM在数学基准测试中的表现。 其中,研究人员对GSM8K使用8-shot CoT提示,对MATH使用4-shot CoT提示。 结果显示,AFM-on-device即使在不到Mistral-7B和Gemma-7B一半大小的情况下,也显著优于这两者。 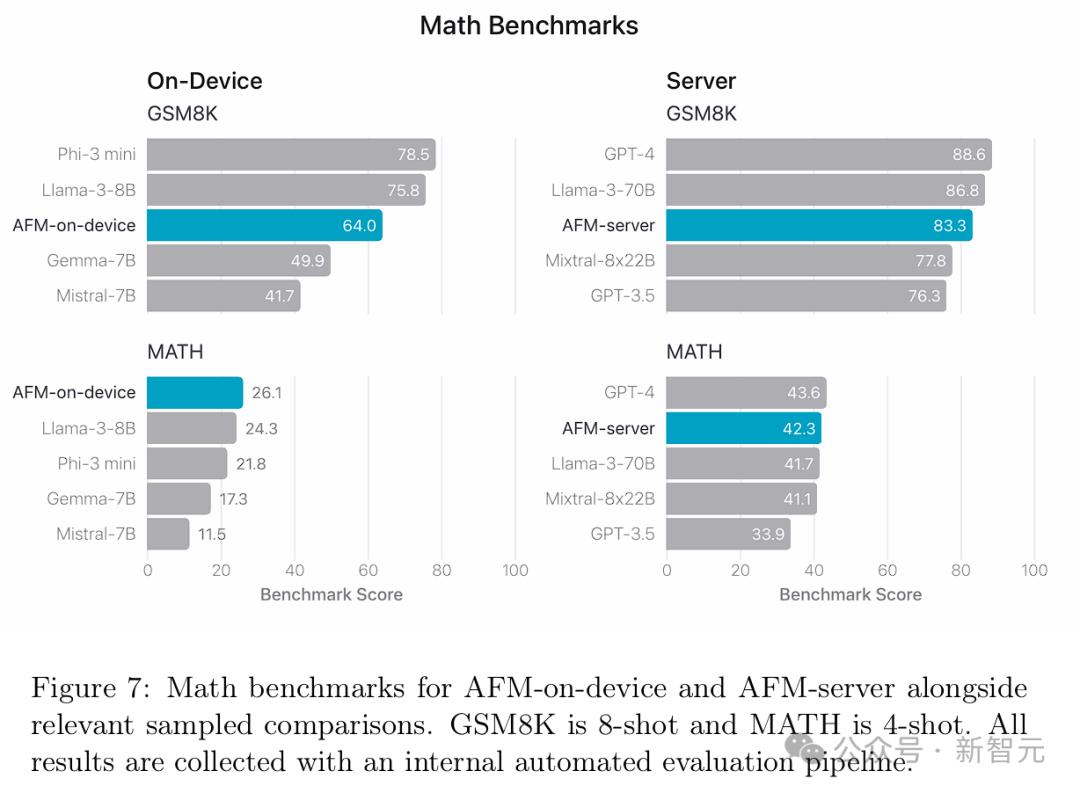
摘要功能 产品团队针对电子邮件、消息和通知的摘要制定了一套定制的指南、指标和专门的评分标准,用于评估摘要质量,采用各种开源、许可和专有数据集。 根据预定义的产品规范,如果任何子维度被评为「差」,则该摘要被归类为「差」。同样,只有当所有子维度都被评为「好」时,摘要才被归类为「好」。 图8显示,AFM-on-device 适配器的整体表现,要优于Phi-3-mini、Llama-3-8B和Gemma-7B。 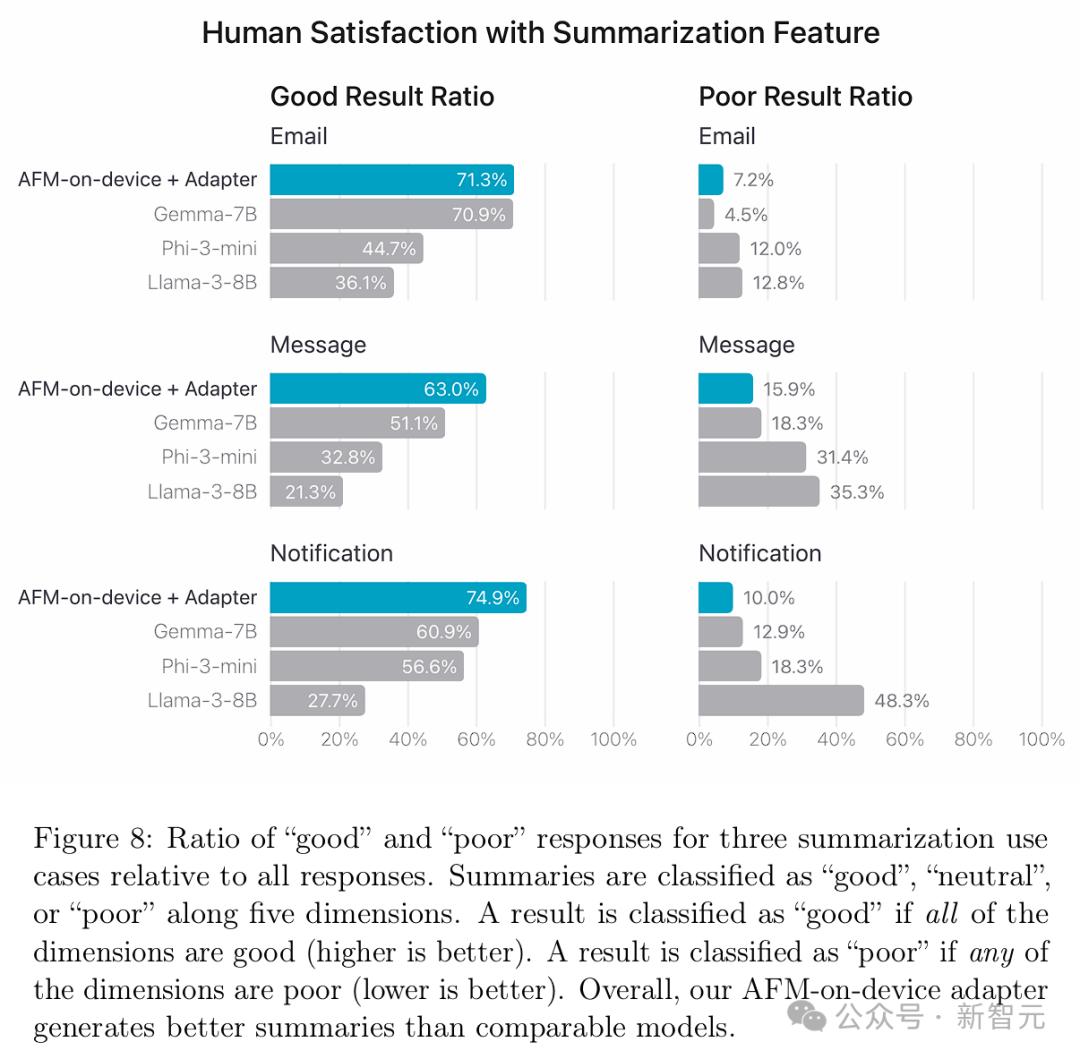
安全评估 图9展示了人类评审针对模型违规的评估结果,数值越低越好。 可以看到,AFM-on-device和AFM-server在应对对抗性提示方面表现出很强的鲁棒性,违规率显著低于开源和商业模型。 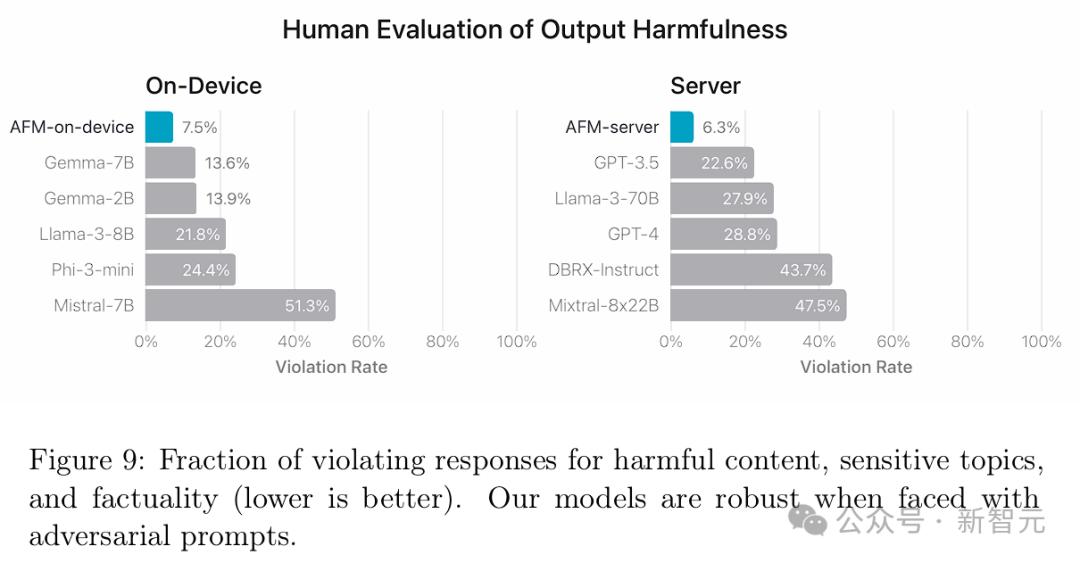
图10则展示了人类评审对于安全评估提示的偏好。 由于可以提供更安全、更有帮助的响应,AFM模型再次拿下一局。 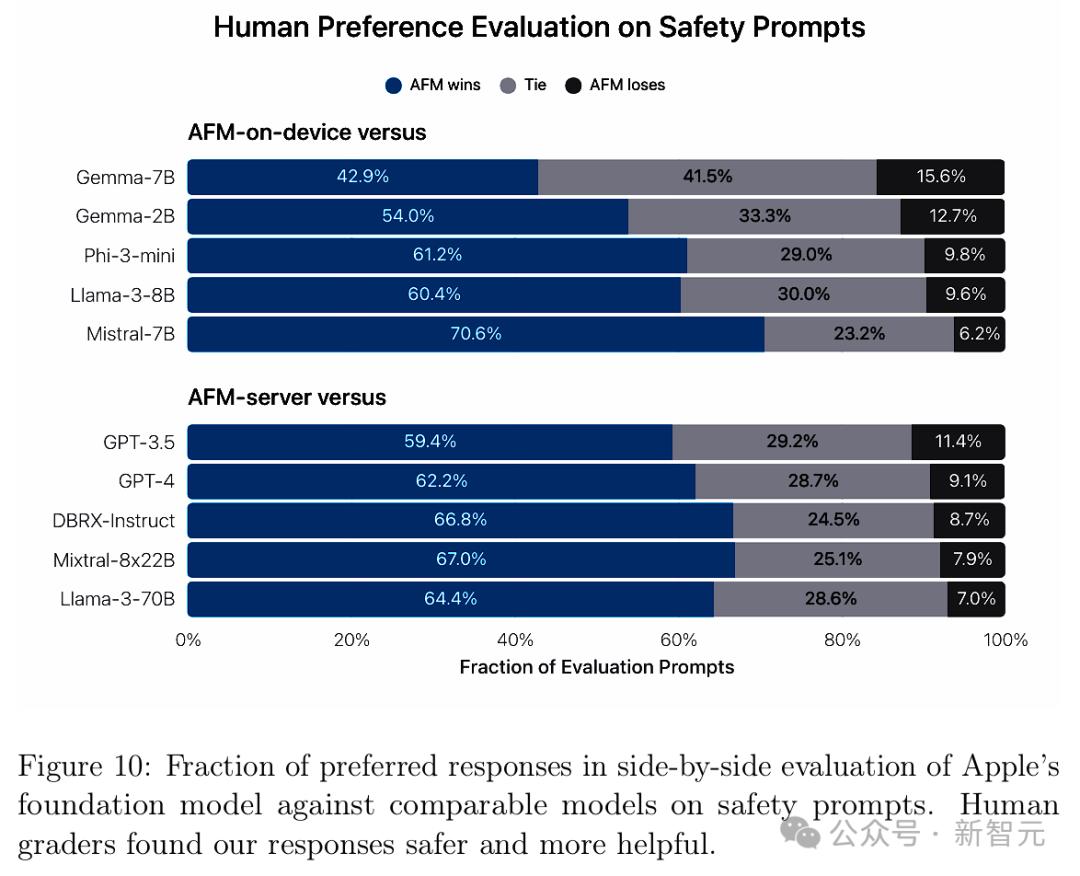
以上,是苹果AI模型的关键一瞥。 苹果AI能力,所有人究竟什么时候可以用得上? 每年,苹果会在秋季发布会上推出新品,iOS 18初始版本将会随着iPhone 16同时推出。 
不过,人人都可体验那时,还需要等到10月。 |







Copyright © 2014-2015 www.foshankj.com All Rights Reserved
[免责声明]本网站的部分文章来源于网络,如有侵权请来邮、来电告知,本站将立即改正,谢谢!
联系电话:0757-83303138 传真:0757-83303136 E-mail:fskjjrxh@163.com
地址:佛山市禅城区同济西路12号永丰大厦9楼912室
佛山金葵建设工程服务有限公司 版权所有
 Loading... Loading...
Loading... Loading...